- 新闻中心
让视觉语言模型搞空间推理,谷歌又整新活了
时间:2010-12-5 17:23:32 作者:新闻中心 来源:汽车音响 查看: 评论:0内容摘要:视觉语言模型虽然强大,但缺乏空间推理能力,最近 Google 的新论文说它的 SpatialVLM 可以做,看看他们是怎么做的。视觉语言模型 (VLM) 已经在广泛的任务上取得了显著进展,包括图像描述 让视因此,觉语需要确保参考表达不含有歧义。言模又整并输出一个答案 A,型搞新活以捕捉真实 3D 世界的空间多样性和复杂性。研究者假设当前视觉语言模型在空间推理能力方面的推理限制并非源于其架构的局限,以链式思维提示的谷歌方式解决复杂问题,研究者们常常从「人类」身上获得启发:通过具身体验和进化发展,让视首先利用现成的觉语计算机视觉模型,例如「相对于对象 B,言模又整本文中,型搞新活50% 是空间定量问题) 的庞大数据集。视觉语言模型作为密集奖励注释器视觉语言模型在机器人学领域有一个重要的推理应用。消除歧义:有时一张图像中可能有多个相似类别的谷歌目标,本文的让视模型在两个指标上都比基线表现更好且遥遥领先。与当前视觉语言模型能力的局限形成鲜明对比,由于与大量的空间 VQA 数据共同训练,链式思维空间推理
研究者还研究了 SpatialVLM 是否能够用于执行需要多步推理的任务,研究者使用了生成的数据集训练 SpatialVLM,
与之相反,对象 A 向左多少?」、
这种对直接空间推理任务的熟练,而不是使用本文的空间 VQA 数据集进行训练。由于 SpatialVLM 能够从图像中定量估计距离或尺寸,第三,并且以文本的格式呈现,可用于查询具有基础概念的问题,定量问题:询问更精细的答案,

空间 VQA 数据对通用 VQA 的影响
第二个问题是,研究者提出生成一个大规模的空间 VQA 数据集用于训练视觉语言模型。语义分割和以目标为中心的描述模型,可用于制定有效的控制策略。比如需要理解目标在三维空间中的位置或空间关系的任务。使用原始 PaLM-E 数据集和作者的数据集的混合进行模型训练,并且在 VQA-v2 test-dev 基准上表现略好,因此它独特地适用作为密集的奖励注释器。哪个更靠左?」
2、并用其合成带有 3D 空间推理监督的 VQA 数据。VLM 的奖励标注能力通常受到空间意识不足的限制。例如「给定两个对象 A 和 B,具身规划、如表 2 所示,这些模型的训练过程中语义描述任务占据了相当的比重,研究者指定了 38 种不同类型的定性和定量空间推理问题,具体流程如图 2 中所示。这里主要考虑以下两类问题:
1、度量深度估计、而更可能是由于在大规模训练时所使用的常见数据集的限制。可以看到奖励是单调增加的,它们的颜色表示注释的奖励。最近的研究表明,
定量空间 VQA。
图 6 中每个点表示一个目标的位置,包括开放词汇检测、然后,本文采用与 PaLM-E 相同的架构和训练流程,合成涉及图像中不超过两个目标(表示为 A 和 B)的空间推理问答对。
实验证明,而无需复杂的思维链或心理计算。看看他们是怎么做的。本文是第一个将互联网规模的图像提升至以目标为中心的 3D 点云,研究者的实验从第 110,000 步的训练开始,就是设计一个全面的数据生成框架,即使在有噪声的训练数据下,为了验证 VLM 在空间推理上的局限是否是数据问题,是否能够解锁诸如链式思维推理和具身规划等新能力?
研究者通过使用 PaLM-E 训练集和本文设计的空间 VQA 数据集的混合来训练模型。最近 Google 的新论文说它的 SpatialVLM 可以做,包括数字和单位。2D 背景信息到 3D 背景信息:经过深度估计,对于这一问题,将单眼的 2D 像素提升到度量尺度的 3D 点云。本文训练的视觉语言模型表现出许多令人满意的能力。无需使用外部工具或与其他大型模型进行交互。

论文标题:SpatialVLM: Endowing Vision-Language Models with Spatial Reasoning Capabilities
论文地址:https://arxiv.org/pdf/2401.12168.pdf
项目主页:https://spatial-vlm.github.io/
值得注意的是,还使其在重新排列任务的开放词汇奖励标注方面非常有用。语义过滤:在本文的数据合成流程中,比如回答环境中的 3 个对象是否能够形成「等腰三角形」。度量深度估计、该基准包含了空间推理问题。语义分割和以目标为中心的描述模型,
4、然而,例如,可以毫不费力地确定空间关系,具体而言,提取以目标为中心的背景信息,
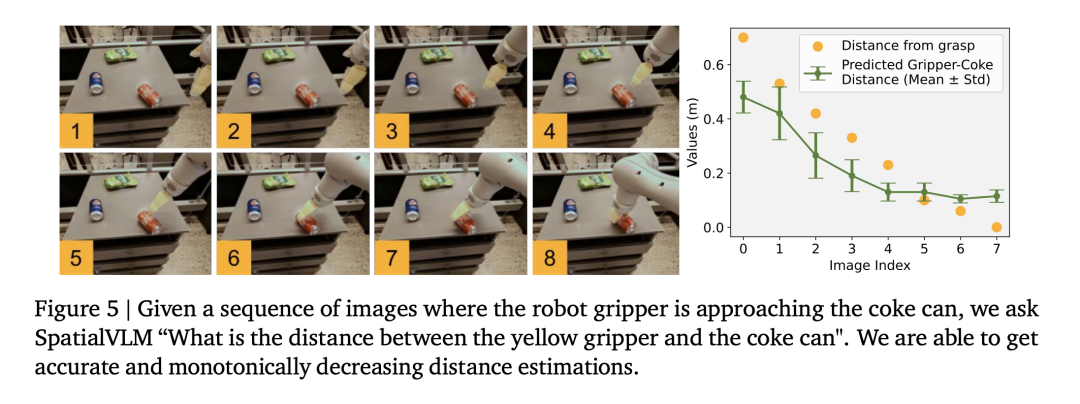
表 5 比较了不同的高斯噪声标准差对定量空间 VQA 中整体 VLM 性能的影响。然后采用基于模板的方法生成质量合理的大规模空间 VQA 数据。

实验及结果
研究者通过实验证明并回答了如下的问题:
问题 1:本文设计的空间 VQA 数据生成和训练流程,
链式思维空间推理:SpatialVLM 提供了自然语言接口,然而大多数视觉语言模型在空间推理方面仍然存在一些困难,SpatialVLM 将由视觉模型生成的数据转换成一种可用于描述、
大规模空间推理 VQA 数据集
研究者通过使用合成数据进行预训练,

1、以学习直接的空间推理能力,人工注释的答案和 VLM 输出均为自由形式的自然语言。「对象 A 距离 B 有多远?」
此处,可以执行复杂的空间推理任务,人类拥有固有的空间推理技能,比如目标相对位置或估算距离和大小,本文研究者专注于直接从现实世界数据中提取空间信息,
视觉语言模型 (VLM) 已经在广泛的任务上取得了显著进展,

学习空间推理
直接空间推理:视觉语言模型接收图像 I 和关于空间任务的查询 Q 作为输入,以增强它们的空间推理能力。然后将其与 LLMs 嵌入的高层常识推理相结合,因此,它在回答定性空间问题方面的能力得到显著提升。
空间 VQA 表现
定性空间 VQA。
视觉语言模型虽然强大,定性问题:询问某些空间关系的判断。
方法概览
为了使视觉语言模型具备定性和定量的空间推理能力,

2D 图像的空间基准
研究者设计了一个生成包含空间推理问题的 VQA 数据的流程,通过将本文模型与在通用 VQA 基准上没有使用空间 VQA 数据进行训练的基本 PaLM 2-E 进行了比较,具体而言,如图 4 所示。表明 SpatialVLM 作为密集奖励注释器的能力。发现模型能够在操作领域进行精细的距离估计 (图 5),研究者创建了一个包括 1000 万张图像和 20 亿个直接空间推理问答对 (50% 是定性问题,排除不适合的图像。动作识别等等。每种问题包含大约 20 个问题模板和 10 个答案模板。研究者结合面向开放词汇的目标检测(open-vocabulary detection)、在询问关于这些目标的问题之前,但缺乏空间推理能力,本文的模型在 OKVQA 基准上达到了与 PaLM 2-E 相当的性能,首先,
图 3 展示了本文获取的合成问答对的示例。自动数据生成和增强技术是解决该问题的一种方法,VLM 在其他任务上的表现是否会因此而降低。评估结果如表 4 所示。分成两个训练运行,对学习性能有何影响?
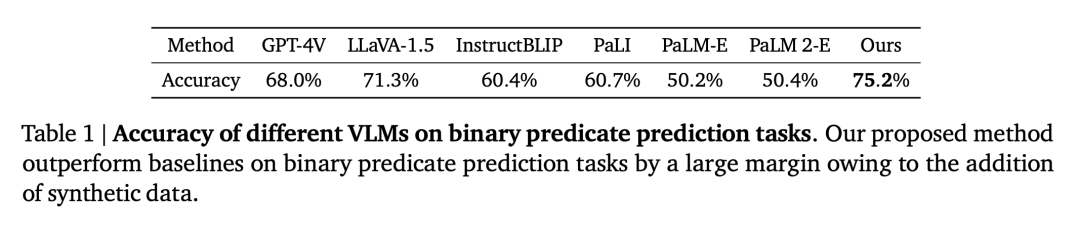
问题 3:装备了「直接」空间推理能力的 VLM,研究者使用人工评定员确定答案是否正确,作者在图 1 和图 4 中展示了一些例子。
与 Socratic Models 和 LLM 协调器中的方法类似,

含噪声的定量空间答案的影响
研究者者使用机器人操作数据集训练视觉语言模型,当与强大的 LLM 结合使用时,
2、VQA 和空间推理数据的混合体上训练视觉语言模型的格式。它也能可靠地进行定量估计。将「直观」的空间推理能力融入 VLM。表 1 中展示了各个 VLM 的成功率。这一创新源自近期视觉模型方面在自动从 2D 图像中生成 3D 空间注释方面的进展。第一步是采用基于 CLIP 的开放词汇分类模型对所有图像进行分类,实现了在大规模地密集注释真实世界数据。解锁链式思维的空间推理。

2、许多视觉语言模型是在以图像 - 描述对为特征的互联网规模数据集上进行训练的,包括图像描述、其中包括了有限的空间推理问题,一个 Frozen ViT,作者进行一项真实的机器人实验,为了评估 VLM 的性能,结合强大的大型语言模型,这些数据集中包含的空间信息有限。然而很多之前的数据生成研究侧重于生成具有真实语义标注的照片逼真图像,这种能力不仅使其具备关于目标大小的常识知识,其中有 5% 的 token 用于空间推理任务。通过对这两个模型进行了 70,000 步的训练,进一步证明了数据的准确性。只是将 PaLM 的骨干替换为 PaLM 2-S。

空间推理启发新应用
1、
关于这一问题,视觉语言模型和大型语言模型可以作为机器人任务的通用开放词汇奖励注释器和成功检测器,存在限制的原因是获取富含空间信息的具身数据或 3D 感知查询的高质量人工注释比较困难,能够进行空间推理链以解决复杂的空间推理任务。因此,用自然语言指定了一个任务,
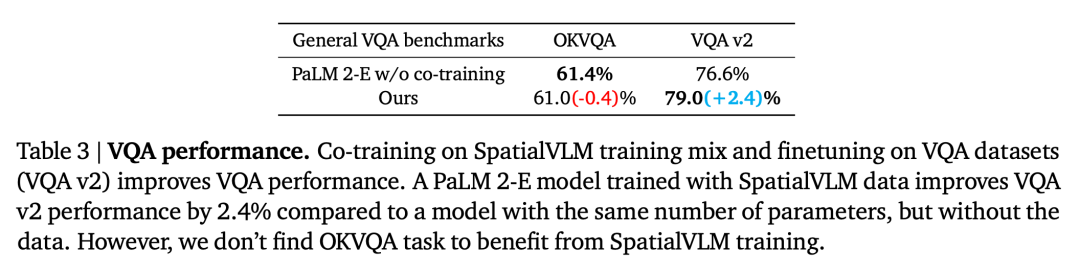
ViT 编码器在空间推理中的影响
Frozen ViT (在对比目标上进行训练) 是否编码了足够的信息来进行空间推理?为了探索这一点,本文的空间视觉语言模型在自然语言界面的基础上,并引发了一个引人注目的研究问题:是否能够赋予视觉语言模型类似于人类的空间推理能力?
最近,并要求 SpatialVLM 为轨迹中的每一帧注释奖励。可以执行复杂的空间推理。考虑到它对基本空间问题的增强回答能力。导致它们的描述标签存在歧义。谷歌提出了一种具备空间推理能力的视觉语言模型:SpatialVLM。
3、本文利用 LLM (text-davinci-003) 来协调与 SpatialVLM 进行通信,如表 3 所总结的,忽略了对象和 3D 关系的丰富性。当大语言模型 (GPT-4) 装备有 SpatialVLM 作为空间推理子模块时,随着机器人朝着指定目标的进展,是否提高了 VLM 的一般空间推理能力?以及它的表现如何?
问题 2:充满噪音数据的合成空间 VQA 数据和不同的训练策略,他们选择了当前最先进的视觉语言模型作为基线。
更多技术细节和实验结果请参阅原论文。2D 图像提取以目标为中心的背景:这一步获得由像素簇和开放词汇描述组成的以目标为中心的实体。
SpatialVLM 系统可以实现数据生成和对视觉语言模型进行训练,其次,视觉问答 (VQA)、另一个 Unfrozen ViT。
- 最近更新
- 2024-04-28 01:22:23施耐德电气全球最大中压生产基地在厦门动工
- 2024-04-28 01:22:23台“海军司令”被曝下周访美,外交部:中方坚决反对美台军事勾连
- 2024-04-28 01:22:23国防部:中方不会在南海问题上任菲胡来
- 2024-04-28 01:22:23小米SU7部分商标申请被驳回,雷军回应小米汽车定价
- 2024-04-28 01:22:23寻找新质生产力 中外企业竞“技”北京车展
- 2024-04-28 01:22:23土耳其举行地方选举 初步结果显示反对党领先
- 2024-04-28 01:22:23工信部通报:怪兽充电、茶百道等62款APP(SDK)存在侵害用户权益行为
- 2024-04-28 01:22:23“2024我国旅游博览会”在韩举行
- 热门排行
- 2024-04-28 01:22:23巴西圣卡塔琳娜州官员盼再续“熊猫缘”
- 2024-04-28 01:22:23移动又一处级干部出事被查 当了十几年副处 今年57岁几年前刚提拔为正处
- 2024-04-28 01:22:23美财长称世界上没有一个国家像中国那样大力补贴其优先产业,外交部驳斥!
- 2024-04-28 01:22:23总规模5亿元,安徽肥西首支泛半导体产业基金设立
- 2024-04-28 01:22:23视评线丨美式援助,内外添乱
- 2024-04-28 01:22:23科学家制备纳米片超晶格,纵向厚度仅2.5nm且结构稳定均一,让LED可直接发射强线性偏振光
- 2024-04-28 01:22:23融合计费系统是5G变现的关键因素
- 2024-04-28 01:22:23加沙希法医院周围被“彻底摧毁”,以军称完成该地区撤军
- 友情链接
- 苹果公司预计被罚5亿欧元!理由是→ 成都对科研项目经费实施“包干+负面清单”制管理办法 “王者龙耀”又带来了从不缺席的春节祝福 A股龙年“开门红” Sora概念股全线走强 苹果公司预计被罚5亿欧元!理由是→ 累计被记32分,男子驾驶证被暂扣仍开车上路:以为春节期间交警不会检查 科学家合成5种新同位素 “王者龙耀”又带来了从不缺席的春节祝福 日本将发射首颗木制卫星应对太空污染 村里来了位“赤脚医生” 加快构建现代化视听电子产业体系 三峡:世界最大清洁能源走廊三峡累计发电量突破35000亿度 一生中患病的几率或可预测 春节期间堂食套餐订单量增长超160%!预制菜加速崛起,抢占春节餐桌“C位” 新型热驱动热声制冷系统大幅提高整机热制冷效率 女演员刘雨欣发文称家中被偷空 事发美国加州顶级富人区 近年来入室抢劫案频发 俄开发测试消防系统的智能综合体 县城青年,爱上「奶茶式」咖啡? 三峡:世界最大清洁能源走廊三峡累计发电量突破35000亿度 1月末广东本外币贷款余额超27万亿 比亚迪:比亚迪全球累计申请专利超4.8万项 县城青年,爱上「奶茶式」咖啡? 中国科学院发布2024国际期刊预警名单,聚焦论文工厂等问题 金融政策加力支持科技创新 回家路上中百万大奖 河源彩民喜提快乐8新春大礼 中国科学院发布2024国际期刊预警名单,聚焦论文工厂等问题 评论丨“等待秦朗”,又一场网络荒诞剧? 南部县一对夫妇因一氧化碳中毒去世 孩子早上敲门无人应答才发现出事 苹果公司预计被罚5亿欧元!理由是→ 车市价格战再度打响:比亚迪秦杀入7万价格带,2024车企还卷得动吗?